-
RStudio read.csv() 한글 깨짐Development 2019. 8. 31. 12:08728x90
어제, 오늘, RStudio에서 read.csv()로 한글이 들어 있는, CSV파일을 로딩할 때, 계속 한글이 깨저나와서 이런저런 시도를 해보며, 적지 않은 시간을 보내서, 해당 내용을 공유해 드리려고 합니다. 결과적으로 한글이 잘 나오게는 되었습니다. ^^
- 국민연금 데이터를 가지고 무언가를 만들기 위해서, 한글주소를 처리할 필요가 생겼습니다.
- 아래의 전국 시/군/구/동의 주소 데이터를 RStudio의 read.csv()로 로딩하는대, 계속 한글이 깨졌습니다.
테스트한 환경
- OS : Windows 10,
- R : 3.6.1
- RStudio : 1.2.1335
우선은 데이터가 UTF-8이어야 함
엑셀을 사용해서 법정동코드(실제주소) 엑셀파일(아래 참고)을 열고, UTF-8의 CSV 형태로 저장합니다.
KIKcd_B.20190701.xlsxread.csv() UTF-8이 맞나? CP949가 맞나?
한글이 포함된 CSV 파일을 읽어올 때, 깨지는 문제에 대해서 검색해 보면, Mac에서 한 방법, UTF-8으로 하면 된다고, 적혀있기도 하고... 몇가지 해결방안 들이 나오는대... 이 글에서 무엇이 맞는지 좀더 알아 보겠습니다.
Windows에서 한글이 어떻게 처리되는가?
R을 떠나서, Windows에서는 한글이 처리되는 방식을 알아 봅시다, 아래와 같이 크게 2가지 방식으로 처리 합니다.
- UTF-8 <- 유니코드(Unicode)
- CP949 <- 유니코드 아님(Non-Unicode)
어떤 방식으로 처리할지는 해당 어플리케이션이 컴파일될 때, 유니코드 버전으로 컴파일을 하면 UTF-8으로 처리되고, 그렇지 않으면, CP949로 한글을 처리하도록 컴파일이 됩니다.
R에서는 한글이 어떻게 처리되는가?
그럼 RStudio(or R)은 한글을 어떤 방식으로 처리하는가? 하는 질문이 따라 오게 됩니다. 제가 확인한 바로는 아래와 같습니다.
- R은 데이터를 읽어 올때는 UTF-8및 다양한 인코딩 사용가능
- 읽어온 데이터를 출력할 때는, Non-Unicode 방식으로 처리 합니다.
즉, 읽어 올 때는, 다양한 인코딩을 사용할 수 있기 때문에, read.csv()에 fileEnfileEncoding 인자를 명확히 지정해야 합니다. 여기서는 법정도주소 파일을 엑셀을 사용해서, UTF-8 명시적으로 변환했기 때문에 fileEnfileEncoding = 'UTF-8' 이 맞습니다.
읽어오는 것까지는 해결이 되었구요, 문제는 화면에 보이기 입니다. 이 부분은 Windows의 '설정' 부분을 좀 자세히 들여다 봐야 합니다.
Non-Unicode어플리케이션일 때, Windows는 어떻게 인코딩을 결정하는가?
앞에서 Windows가 Non-Unicode일 때, CP949로 처리한다고 말씀 드렸는대, 사실 CP949는 Non-unicode인대 한글을 사용할 수 있는 Non-Unicode 인코딩 방식 중에 하나입니다.
euc-jp(일본어의 경우)등 여러가지 인코딩을 사용할 수 있습니다. 문제는 어플리케이션이 컴파일될 때, 사용한 인코딩옵션이 CP949이고, CP949로 맞게 설정하면, 글자가 잘 보이구요, 틀리면 글자가 깨저 나와요. 어떤게 맞는지 알 수 있는 방법이 없습니다. 이런 문제 때문에 Unicode를 사용해서, 인코딩을 맞춰야 하는 문제를 해결한 것이지요.
Windows의 '설정'에서는 아래 그림과 같습니다. '한국어'를 선택하면, Non-Unicode어플리케이션이 언어를 처리할 때, CP949 인코딩이 사용됩니다.
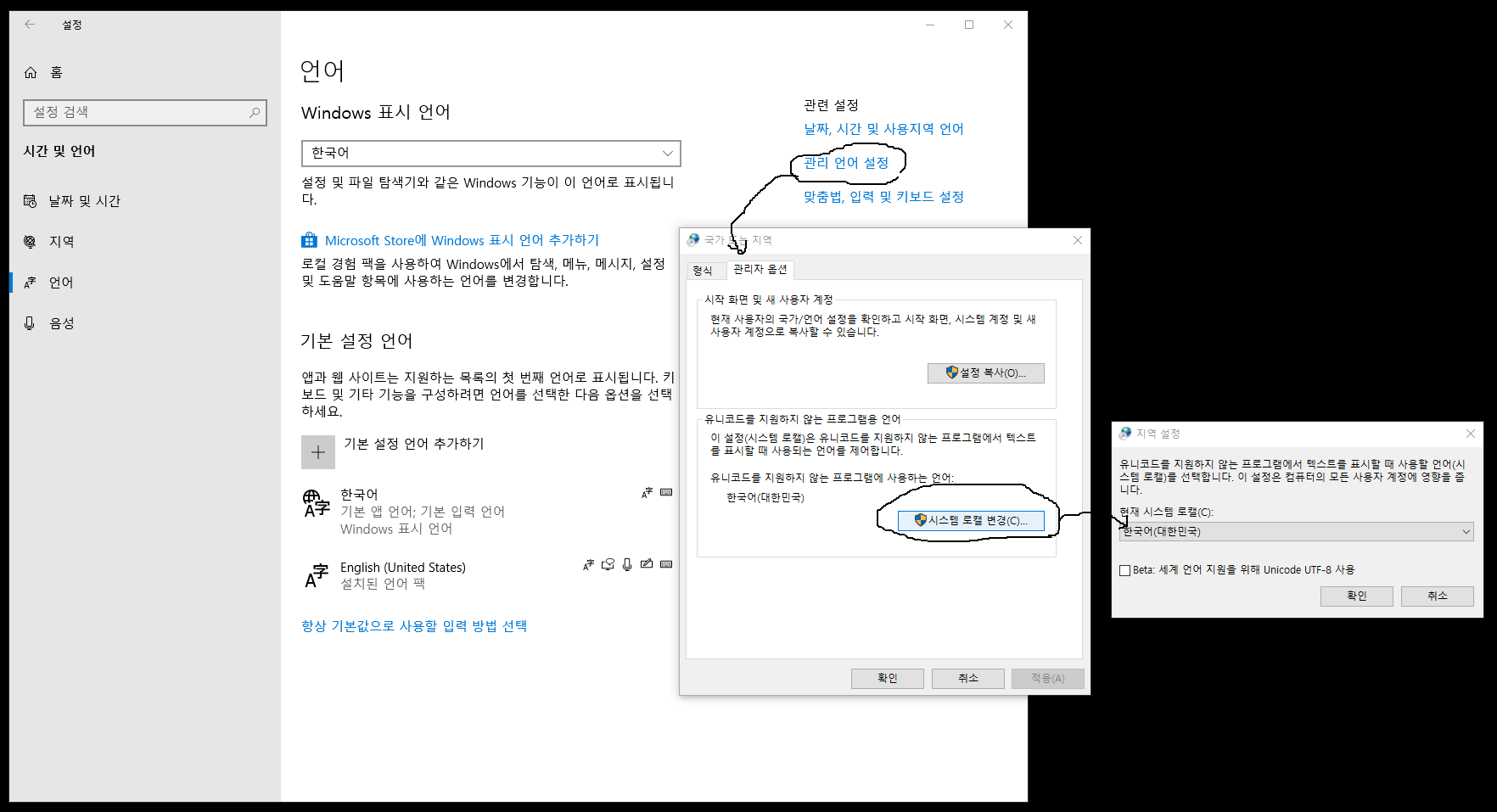
RStudio(or R)은 언어를 화면에 표시 할때, 어떤 인코딩을 사용하는가?
제가 확인한 바로는 바로 위의 Non-Unicode에서 설정한 인코딩을 사용합니다.
따라서, 언어를 화면에 표시할 때는, CP949를 사용하는 것 같습니다.
즉, read.csv()에서 encoding = 'CP949'를 사용하는 것이 맞습니다. 제가 테스트한 환경에서는 자동으로 Non-Unicode인코딩을 사용해서, 따로 encoding 인자를 주지 않아도, 자동으로 CP949를 사용하는 것으로 생각됩니다.
마지막으로 예외의 경우 Windows 표시 언어 가 '한국어' 가 아닌경우
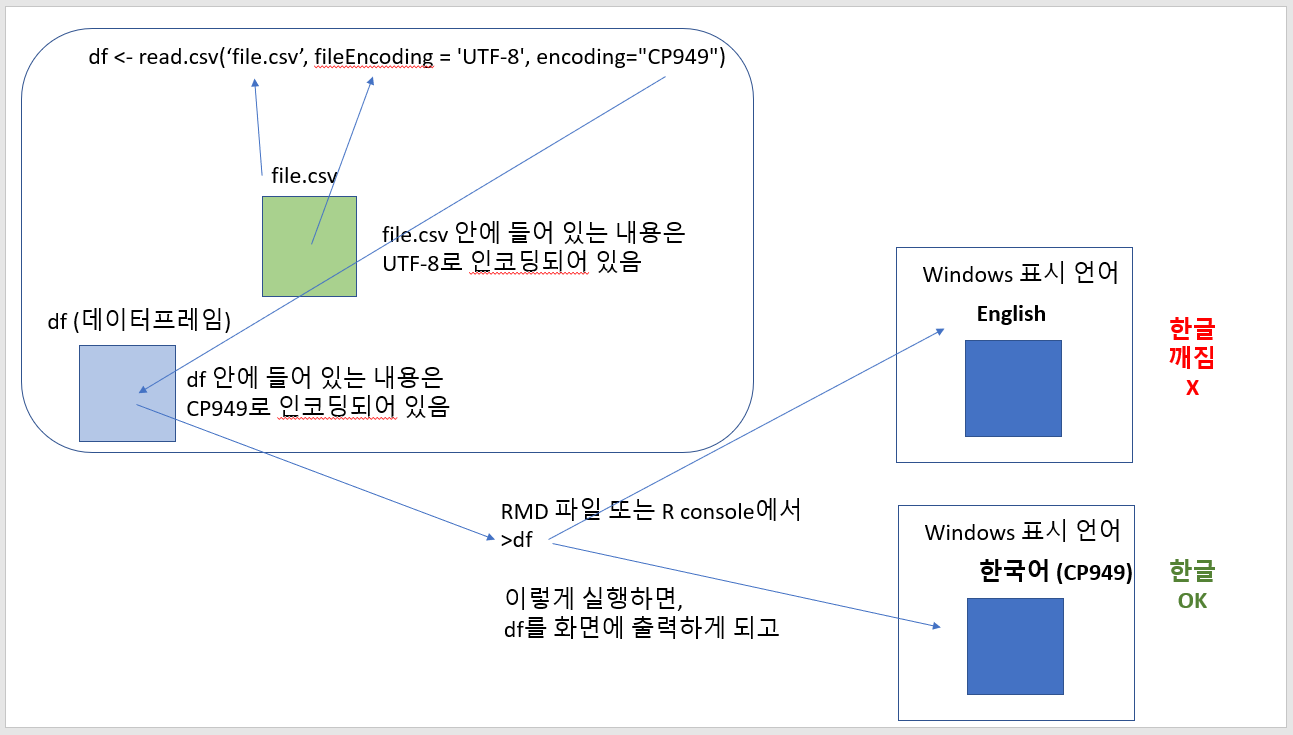
사실 제가 이 경우여서, 해결하는대 시간이 많이 걸렸습니다. 결론 부터 이야기 드리면, 'Windows 표시 언어' 를 '한국어'로 사용하세요. 이 부분이 'English'(영어)로 설정되어 있다면, 한글 CSV를 화면에 올바르게 표시할 방법이 없습니다.
아래와 같이 df 라는 데이터 프레임이 CP949로 되어 있기 때문에, Windows 표시 언어가 꼭, 한국어로 되어 있어야 합니다.
 728x90
728x90'Development' 카테고리의 다른 글
R에서 국민연금 OpenAPI사용하기 (0) 2019.09.09 R에서 한국지도 그려보기 (Drawing South Korea map in R) (0) 2019.09.07 [synergy-sharing-audio] buy old laptop for development purpose (0) 2019.07.15 [synergy] building synergy from source on windows (0) 2019.07.12 [synergy] build setup on windows 10 (0) 2019.07.11